
横浜国立大学理工学部建築都市環境系学科卒
一級鉄筋技能士
唎酒師
今回はnumpyの習得をしていきます。
numpyはpythonでは必須ライブラリになりますので、しっかり習得しましょう。
numpyは配列と同じです。数値の計算、行列演算で使われています。
また、機械学習の計算は行列計算が多いので、このnumpyに慣れておくと良いです。
本記事のサンプルコード

目次
numpyについて
numpyは数値演算を高速にできるライブラリです。
データは多次元のデータを扱うことが多いです。
例えば、表データ解析、画像処理、機械学習の計算をすることができます。
インストール
インストールは他のライブラリと同じように、pipを使います。
|
1 |
pip install numpy |
読み込み
読み込みは次のように決まっています。
|
1 |
import numpy as np |
他の人も全てこの書き方ですので、このまま使いましょう。
numpyの基礎
では、基礎を習得していきましょう。
データを作る
まず、データを作ってみましょう。
ゼロや乱数などを作っていきます。
ゼロ値
ゼロの値は、zerosメソッドを使います。
|
1 2 3 |
# 1次元でゼロを3つ a = np.zeros(3) print(a) |
|
1 |
[0. 0. 0.] |
1の値
1の値は、onesメソッドを使います。
|
1 2 3 |
# 2次元で1を 2×4を作成 a = np.ones([2,4]) print(a) |
|
1 2 |
[[1. 1. 1. 1.] [1. 1. 1. 1.]] |
乱数
乱数は、色々な方法がありますが、0-1の乱数はrandom.randを使います。
他は、下記のリンクを参考ください。
|
1 2 3 |
# 1次元で0-1の乱数を3つ a = np.random.rand(3) print(a) |
|
1 |
[0.73866986 0.95248467 0.46058571] |
eye
単位行列はeyeメソッドを使います。
単位行列なので、3×3など行列同じ数値なので、1つの数値を渡します。
|
1 2 3 |
# 3×3の単位行列 a = np.eye(3) print(a) |
|
1 2 3 |
[[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]] |
list,tupleから作る
listやtupleから変換する方法があります。
arrayメソッドに入れるだけです。
|
1 2 3 4 5 6 |
# リストから作る list_a = [[1,2,3], [4,5,6], [7,8,9]] a = np.array(list_a) print(a) |
|
1 2 3 |
[[1 2 3] [4 5 6] [7 8 9]] |
データを取り出す
データを取り出してみましょう。
まず、1次元からみていきましょう。
基本的には、listと同じです。
|
1 2 3 4 5 6 |
# 1次元 a = np.array([1,2,3,4,5]) # 1つ取り出す print(a[1]) # 複数取り出す print(a[1:4]) |
|
1 2 |
2 [2 3 4] |
indexは0から始まります。
複数取得の場合、開始index:終了indexとするけど、終了indexの1つ前までのデータを取り出します。
次に、2次元です。listは各次元を[]で区切ります。
numpyの場合は、各次元をカンマ「,」で区切って欲しいデータを取得します。
コードで確認しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 2次元 list_a = [[1,2,3], [4,5,6], [7,8,9]] a = np.array(list_a) # listの場合 print(list_a[1][1:3]) # numpyの場合 print(a[1, 1:3]) |
|
1 2 |
[5, 6] [5 6] |
同じデータを取り出していますが、記述が違いますね。
多次元配列はnumpyを使うことが多いので、この記述にも慣れておきましょう。
データ読み込み
データを読み込んで、numpyで計算するという方法はよく使います。
ファイルからlistやpandas.DataFrameに読み込んで、numpyのメソッドを使う方法があります。
まず、ファイルから読み込んでみます。
次の内容の「sample.txt」を読み込みます。
|
1 2 3 |
1,2,3 4,5,6 7,8,9 |
コメント入れてありますので、処理を順番にみていってください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# ファイルからlist そして numpyに list_a = [] with open('sample.txt') as f: # 1行ずつ読み込み for d in f.readlines(): # 改行を削除 txt_line = d.rstrip() # カンマ区切りで分けて、list_aに追加 list_a.append(txt_line.split(',')) # listの表示 print(list_a) # numpyに変換 a = np.array(list_a) print(a) |
|
1 2 3 4 |
[['1', '2', '3'], ['4', '5', '6'], ['7', '8', '9']] [['1' '2' '3'] ['4' '5' '6'] ['7' '8' '9']] |
次に、numpyのloadtxtメソッドを使ってみます。
区切り文字はカンマですが、delimiterで指定できます。
|
1 2 3 |
# loadtxtメソッド、区切り文字に「,」を指定 a = np.loadtxt('sample.txt', delimiter=',') print(a) |
|
1 2 3 |
[[1. 2. 3.] [4. 5. 6.] [7. 8. 9.]] |
メソッド使った方が楽ですね。
データの形の確認
計算している過程で、データの次元数など形が変わっていくので、わからなくなったら、データの形を確認しましょう。
データの形は、何次元で、各次元何個ずつデータがあるかということです。
確認には、shapeを使います。
確認してみましょう。
|
1 2 3 |
a = np.array([[1,2,3], [4,5,6]]) print(a.shape) |
|
1 |
(2, 3) |
2行×3列のデータなので、(2, 3)と出ます。
3次元になると(1次元数, 2次元数, 3次元数)と続きます。
四則演算
四則演算では、同じ要素同士を計算します。
aとbを用意して、四則演算をしてみます。
|
1 2 3 4 5 6 7 8 9 |
# 四則演算 a = np.array([[1,2,3], [4,5,6]]) b = np.array([[1,2,3], [4,5,6]]) print('足し算\n', a+b) print('引き算\n', a-b) print('掛け算\n', a*b) print('割り算\n', a/b) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
足し算 [[ 2 4 6] [ 8 10 12]] 引き算 [[0 0 0] [0 0 0]] 掛け算 [[ 1 4 9] [16 25 36]] 割り算 [[1. 1. 1.] [1. 1. 1.]] |
ブロードキャスト
numpyではブロードキャストという考えがあります。
先ほど、四則演算をしましたが、全部の要素に1を足すときに、同じ行列数分の1を用意するのでは、面倒ですね。
なので、多次元のデータでも1を足すだけで、ブロードキャストでは次のように、行列数を増やして足してくれます。
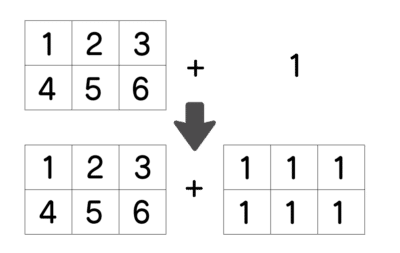
コードで、みてみましょう。
|
1 2 3 4 5 |
# 1を足す a = np.array([[1,2,3], [4,5,6]]) b = 1 print(a+b) |
|
1 2 |
[[2 3 4] [5 6 7]] |
全部の要素に1が足されています。
このブロードキャストは、行数が同じデータがあれば、それをコピーして足してくれます。
例えば、2行 × 1列のデータを足してみます。
|
1 2 3 4 5 6 7 8 9 |
# 1を足す a = np.array([[1,2,3], [4,5,6]]) b = np.array([[1], [2]]) # 形確認 print("データの形確認", a.shape, b.shape) # 同じ行数の(2, 1)を足し算 print(a+b) |
|
1 2 3 |
データの形確認 (2, 3) (2, 1) [[2 3 4] [6 7 8]] |
これは、次の図のように、2×3と2×1を足し算しています。
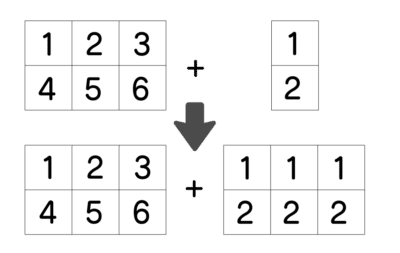
列数の数を合わせて(1, 3)のデータを足しても、計算してくれるので、試してみてください。
行列の積
numpyでは行列の積もdotメソッドで簡単にできます。
2×3 と 3×2の積をしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
a = np.array([[1,2,3], [4,5,6]]) b = np.array([[1,2], [3,4], [5,6]]) # 形確認 print("データの形確認", a.shape, b.shape) # 積 c = np.dot(a,b) print(c) print(c.shape) |
|
1 2 3 4 |
データの形確認 (2, 3) (3, 2) [[22 28] [49 64]] (2, 2) |
計算があっているか確認するのは面倒なので、しなくて良いですが、行列の積の計算を忘れている方は、下記のwikiで確認しておきましょう。
並び替え
並べ替えでは、sortメソッドを使っていきます。
まず、1次元からみていきましょう。
|
1 2 3 4 |
# 1次元の並び替え a = np.array([3,2,4,1,5]) a_sort = np.sort(a) print(a_sort) |
|
1 |
[1 2 3 4 5] |
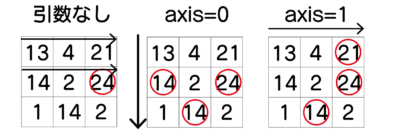
次は、2次元です。
2次元では、どの次元を並び替えるかの指定をaxis=対象次元-1で指定します。
対象次元を1次の並べ替えなら0、2次の並び替えなら1です。
まず、1次の方をみてみましょう。
|
1 2 3 4 5 6 |
# 2次元の並び替え a = np.array([[3,13,21], [4,11,24], [1,14,23]]) a_sort = np.sort(a, axis=0) print(a_sort) |
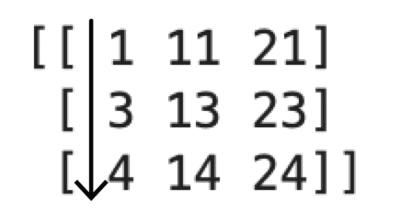
次に、2次の方をみてみます。
|
1 2 3 4 5 6 |
# 2次元の並び替え a = np.array([[13,4,21], [14,2,24], [1,14,2]]) a_sort = np.sort(a, axis=1) print(a_sort) |
どうでしょう、元データが並べ替えられています。
計算
numpyでは、最大値などの計算は一通り良いされています。
| メソッド | 機能 |
| sum | 合計 |
| max | 最大値 |
| min | 最小値 |
| std | 標準偏差 |
| mean | 平均 |
| median | 中央値 |
計算してみましょう。
|
1 2 3 4 5 6 7 |
a = np.array([3,2,4,1,5]) print('合計', np.sum(a)) print('最大値', np.max(a)) print('最小値', np.min(a)) print('標準偏差', np.std(a)) print('平均', np.mean(a)) print('中央値', np.median(a)) |
|
1 2 3 4 5 6 |
合計 15 最大値 5 最小値 1 標準偏差 1.4142135623730951 最大値 3.0 最大値 3.0 |
numpyの応用
より詳しくみていきましょう。
reshape
データの、行列数は変更することができます。
変更は、reshapeメソッドを使います。
引数に、変形したい次元数をリストで渡します。
2×3を2×3に変えてみます。
|
1 2 3 4 5 6 7 |
a = np.array([[1,2,3], [4,5,6]]) print('shape前', a.shape) a_reshape = a.reshape([3,2]) print('shape後', a_reshape.shape) a_reshape |
|
1 2 3 4 5 6 |
shape前 (2, 3) shape後 (3, 2) [69]: array([[1, 2], [3, 4], [5, 6]]) |
このように、データの形を変更することができます。
転置
次は転置です。
転置を忘れた方は、下記のWikiを確認しておいてください。
>> wiki 転置
転置はTとするだけです。
|
1 2 3 4 5 6 7 |
a = np.array([[1,2,3], [4,5,6]]) print('転置前', a.shape) a_t = a.T print('転置後', a_t.shape) a_reshape |
|
1 2 3 4 5 6 |
転置前 (2, 3) 転置後 (3, 2) [72]: array([[1, 2], [3, 4], [5, 6]]) |
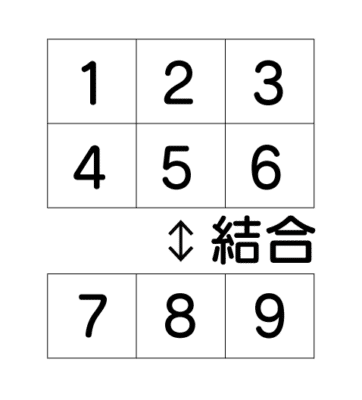
結合
次は結合を見ていきます。
結合は縦方向、横方向があります。
まず、縦方向の結合を見てみましょう。vstackメソッドを使います。
vstackの引数に結合するデータ2つを入れます。列数があっている必要があります。
|
1 2 3 4 5 6 7 8 |
# vstack a = np.array([[1,2,3], [4,5,6]]) b = np.array([[7,8,9]]) c = np.vstack((a, b)) print(c.shape) print(c) |
|
1 2 3 4 |
(3, 3) [[1 2 3] [4 5 6] [7 8 9]] |
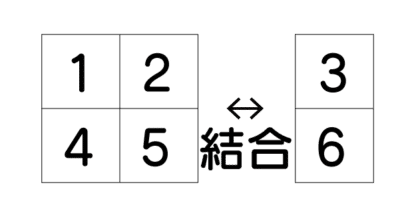
次は横方向に結合します。hstackメソッドを使います。
hstackの引数に結合するデータ2つを入れます。行数があっている必要があります。
|
1 2 3 4 5 6 7 8 9 |
# hstack a = np.array([[1,2], [4,5]]) b = np.array([[3], [6],]) c = np.hstack((a, b)) print(c.shape) print(c) |
|
1 2 3 |
(2, 3) [[1 2 3] [4 5 6]] |
データの連結もそうですが、画像データを横並びに連結することもできます。
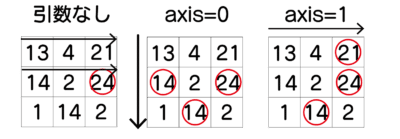
argmax, argmin
argmax,argminを使うと、最大、最小値の場所をindexを取得できます。
sortのところでも出ましたが、axisで指定します。
axisを省略した場合は、全部のデータの最大値の場所を取得できます。
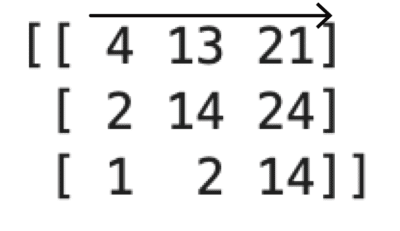
取得する番号は0からの番号になります。
みていきましょう。
axisを省略して場合。
|
1 2 3 4 5 6 |
# 全部の最大値 a = np.array([[13,4,21], [14,2,24], [1,14,2]]) a_max = np.argmax(a) print(a_max) |
|
1 |
5 |
axis=0の場合。
|
1 2 3 4 5 6 |
# 1次の最大値 a = np.array([[13,4,21], [14,2,24], [1,14,2]]) a_max = np.argmax(a, axis=0) print(a_max) |
|
1 |
[1 2 1] |
axis=1の場合。
|
1 2 3 4 5 6 |
# 2次の最大値 a = np.array([[13,4,21], [14,2,24], [1,14,2]]) a_max = np.argmax(a, axis=1) print(a_max) |
|
1 |
[2 2 1] |
argminは各自で試してみてください。
これは、機械学習の分類結果とかは、[0.3, 0.1, 0.7]などの0-1のスコア値で受け取ることがあり、どこのスコアが高いか確認する場合とかに使います。
まとめ
以上、numpyの使い方になります。
numpyはpythonでは必須ライブラリです。機械学習の計算は行列計算が多いので、numpyに慣れておくと良いでしょう。