

横浜国立大学理工学部建築都市環境系学科卒
一級鉄筋技能士
唎酒師
pythonでは機械学習やデータ解析をすることが多いため、CSVの読み込みなどの操作は必須となります。
データ読み込めなければ、解析もできないのでとても大事です。
データの読み込みでも便利なpandasというライブラリを使っていきます。
pandasは他にもデータベースからもデータが取得できますので、pythonでは必須ライブラリの1つです。

目次
pandasについて
pandasは表データの取り扱いに特化したライブラリです。
もともと、金融データを分析するために開発されたツールで、具体的には以下のようなことができます。
- データの読み込み書き込み
- データ同士の結合
- データの欠損値補完などの加工
pipを使ってインストール
他のライブラリと同じくpipを使ってインストールします
|
1 |
pip install pandas |
pandasではdataframeという型を使う
pandasではdataframeという型を使います。
DataFrameは以下の3つの構成となっています。
- columns(列名)
- index(行名)
- values(値)

pandasではこのようなデータベースや、エクセルなどの表データを取り扱うのが得意なライブラリです。
pandasライブラリをpdとして読み込む
pandasを使うときは下記を実行します。
pandasをpdとして読み込みます。
|
1 |
import pandas as pd |
csvファイルの読み込み
下記のCSV(sample.csv)を読み込んでいきます。
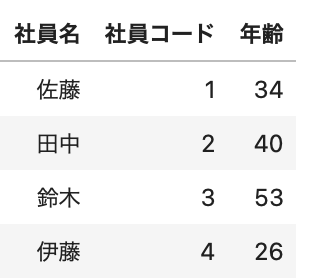
上記リンクのファイルをコードと同じ場所に保存してください。
右クリックで保存できます。
read_csvメソッドで読み込む
読み込みにはread_csvメソッドを使います。
一番シンプルな使い方は、df = pd.read_csv(‘ファイルのパス’)です。

|
1 |
df = pd.read_csv('sample.csv') |
|
1 |
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8e in position 0: invalid start byte |
しかし、エラーが出てしまいます。
英語のみのファイルであれば良いですが、日本語を含む場合は、文字コードを気にする必要があります。
pythonのドキュメントの標準エンコーディングがそのリストになります。
今回は日本語対応の「cp932」を使います。

引数に、encoding=’cp932′を追加します。
|
1 |
df = pd.read_csv('sample.csv', encoding='cp932') |
エラーもなく読み込めました。
shapeメソッドでデータ数を確認
読み込んだデータ数を確認しましょう。
shapeを使います。
|
1 |
df.shape |
|
1 |
(4, 3) |
(行数, 列数)で表示されます。
データを確認するメソッド
データ確認するメソッドがいくつかあります。
| メソッド | 機能 |
|---|---|
| head | データの先頭を確認。引数に確認したいデータ数を入力、省略時は5つ表示。 |
| tail | データの末尾を確認。引数に確認したいデータ数を入力、省略時は5つ表示。 |
| info | 列名や型を確認 |
| describe | 統計値を確認 |
headを確認してみましょう。
|
1 |
df.head() |
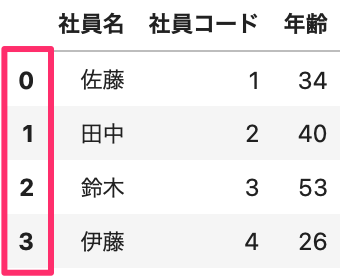
4行しかないので、4行がそのまま表示されます。
赤枠の箇所が、DataFrameのIndex(行名)になります。
CSVには無いIndexが自動で追加されていますが、そういうものなので気にしないでおきましょう。
他のメソッドは各自で動かしてみてください。
データが欠損している場合の読み込み
列名とデータがある、よく見るデータを読み込みましたが、列名がなかったり、データの開始位置がズレていたりする場合があります。
次のようなデータの読み込みを見ていきましょう。
列名のないデータを読み込むには引数をheader=Noneとする
下記のような列名のないデータは、header=Noneとすることで読み込むことができます。
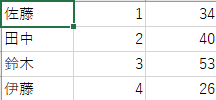
上記リンクをダウンロードして、実行してください。
|
1 2 |
df = pd.read_csv('sample2.csv', encoding='cp932', header=None) df.head() |

headerは列名の開始位置になるのですが、Noneとすることで「ないよ」ということです。
列名がない場合は、0,1,2と自動で割り当てられます。
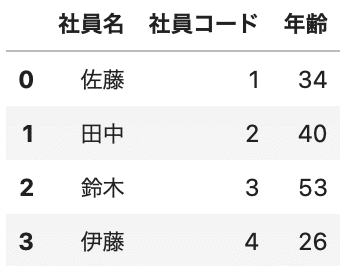
列名は引数にnames=列名のlistを渡すことで列名をつけることができます。
|
1 2 |
df = pd.read_csv('sample2.csv', encoding='cp932', header=None, names=['社員名','社員コード','年齢']) df.head() |
開始位置がずれているデータは引数にheader=列名の開始行数を指定
下記のように、行数をずらして読み込みたい場合は、引数にheader=列名の開始行数を指定します。
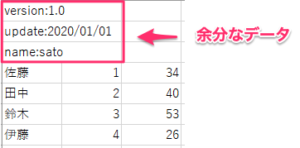
上記リンクをダウンロードして実行してください。
行数は0からカウントするので、今回であれば、header=3とします。
|
1 2 |
df = pd.read_csv('sample3.csv', encoding='cp932', header=3) df.head() |
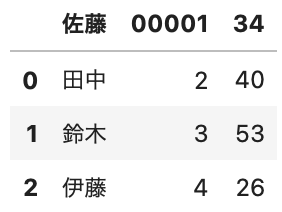
読み込めましたが、データの1行目が列名になってしまっています。
4行目に列名があればOKでしたが、今回のデータはないので、一つ上の行を選びつつ、列名を渡します。
|
1 2 |
df = pd.read_csv('sample3.csv', encoding='cp932', header=2, names=['社員名','社員コード','年齢']) df.head() |
これで列名を含んだデータを取得できました。
読み込み列の指定したい場合は引数にusecolsを使って指定する
列が多い場合、読み込みたい列だけを読み込むこともできます。
usecolsの引数を使っていきます。csvはsampleを読んでいきます。
usecols=列名リストを与えることで、指定した列だけを取得できます。
|
1 2 |
df = pd.read_csv('sample.csv', encoding='cp932', usecols=['社員名', '年齢']) df.head() |
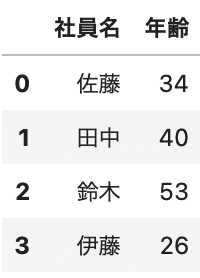
CSVの書き込み
書き込みも読み込みと同様に、文字コード、header、indexの有無を引数に渡しながら、書き込みます。
to_csvメソッドで書き込む
書き込みにはto_csvメソッドを使います。

ファイルパスでファイル名のみを指定すると、コードと同じフォルダに保存されます。
先程、列名を指定して読み込んだので、書き込む前にsample.csvを読み込んでおきます。
|
1 |
df = pd.read_csv('sample.csv', encoding='cp932') |
引数は読み込みと同じで、よく使うのは下記3つです。
| 引数 | 機能 | 初期値(省略時) |
|---|---|---|
| encoding | 文字コードを指定 | utf-8 |
| header | 列名を書き込むかどうか | True 省略時は列名がつく |
| index | 行名を書き込むかどうか | True 省略時は行名がつく |
日本語を含むので、ecoding=’cp932’で列名あり、行名なしで書き込みます。
|
1 |
df.to_csv('output.csv', encoding='cp932', header=True, index=False) |
コードと同じフォルダにoutput.csvが出力されます。
columns=対象の列名リストを引数に指定して書き込む
データ処理などを色々していると、余計な列ができていくため、必要な列のみを保存したい場合があります。
その場合は、columns=対象の列名リストを引数に渡します。
|
1 |
df.to_csv('output.csv', encoding='cp932', header=True, index=False, columns=['社員名', '年齢']) |
列が絞られて、保存されます。
まとめ
pythonでは機械学習やデータ解析をすることが多いため、CSVの読み込みなどの操作は必須となります。
pandasを使用した表データの取り扱いに慣れていきましょう。