

横浜国立大学理工学部建築都市環境系学科卒
一級鉄筋技能士
唎酒師
データ処理においてdescribeメソッドは必要不可欠なメソッドです。
Excel等の表計算ソフトで基本的なデータ処理を行う際には必ず平均や最大値最小値の集計が必要になります。
この記事ではdescribeメソッドの基本操作と文字列データと数値データの場合の使い方について解説します。

目次
describeメソッドについて
describeメソッドの基本について見ていきましょう。
統計情報を瞬時に表示できる
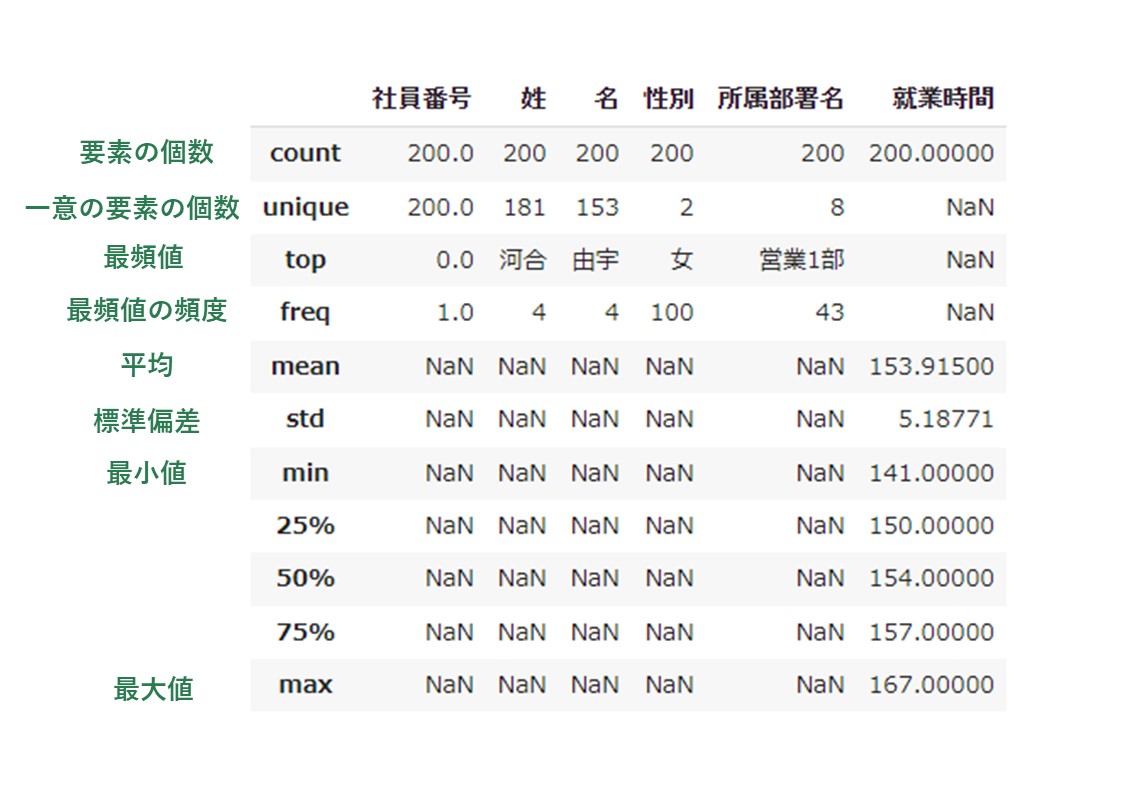
describe()を使えば統計情報を瞬時に抽出することができます。
扱うデータの中には欠損値や外れ値(参考にならない値)が存在することがありますが、これらのエラーを除いた場合の最大値や最小値に値を置換するなどの前処理作業にdescribe()が活躍します。
文字列データの場合と数値データの場合で表示される情報が異なる
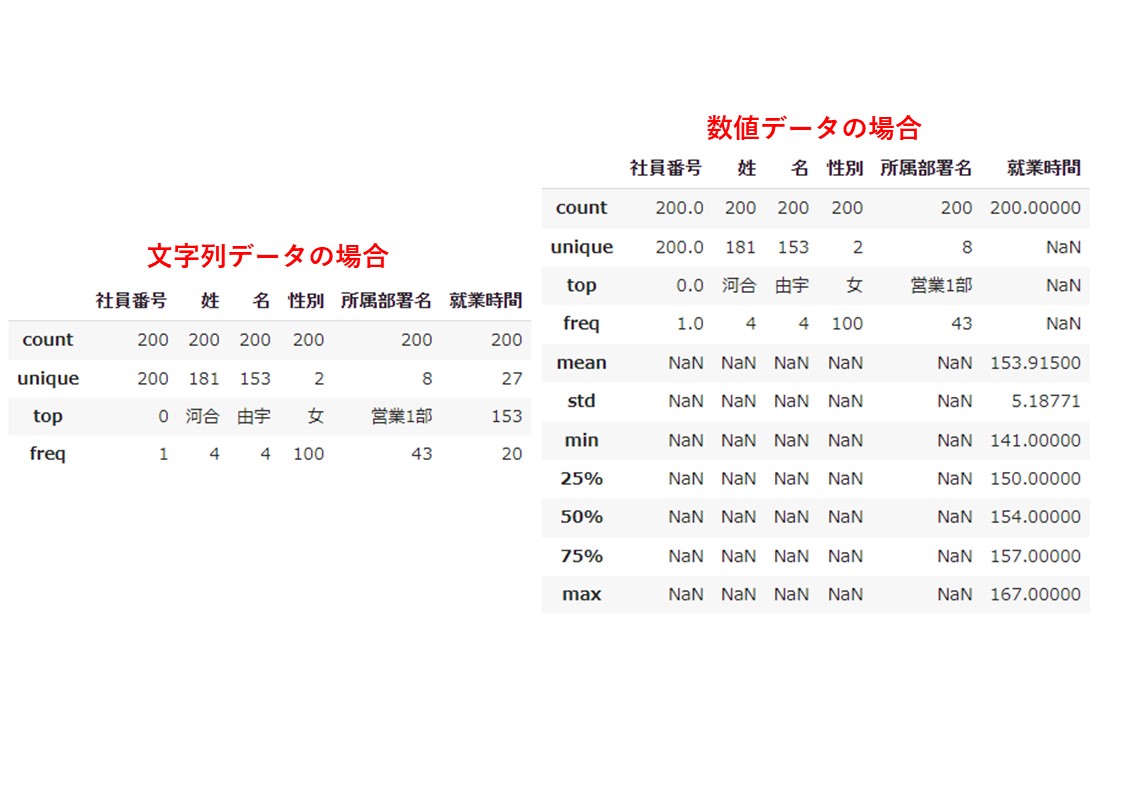
describe()を扱う際の注意点は、データの型によって表示される情報が異なるということです。
数値データの場合にはすべての統計情報が表示されますが、文字列データの場合は平均や標準偏差等の情報は表示されません。
見た目上は数字でもデータの型がint型になっていないとすべての統計情報を表示できないので注意しましょう。
データの型を調べるには.dtypesメソッドを使用します。
|
1 2 3 4 5 6 7 8 9 10 |
df.dtypes #この場合は全て文字列データになっているので平均や標準偏差が表示されない 社員番号 object 姓 object 名 object 性別 object 所属部署名 object 就業時間 object dtype: object |
全ての統計情報を表示するにはデータがint型になっている必要がある。
データがint型になっているかどうか.dtypesで確認しよう。
文字列データを数値データに変換して全ての統計情報を表示する
では実際に文字列データになっているものを数値データに直してみます。
ここでは就業時間の列を修正してみます。
astype(int)メソッドでobject型からint型に変換
上記で見たように、就業時間はobject型になっているので、int型に修正します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#int型に変更 df['就業時間'] = df['就業時間'].astype(int) df.describe() 社員番号 姓 名 性別 所属部署名 就業時間 count 200.0 200 200 200 200 200.00000 unique 200.0 181 153 2 8 NaN top 0.0 河合 由宇 女 営業1部 NaN freq 1.0 4 4 100 43 NaN mean NaN NaN NaN NaN NaN 153.91500 std NaN NaN NaN NaN NaN 5.18771 min NaN NaN NaN NaN NaN 141.00000 25% NaN NaN NaN NaN NaN 150.00000 50% NaN NaN NaN NaN NaN 154.00000 75% NaN NaN NaN NaN NaN 157.00000 max NaN NaN NaN NaN NaN 167.00000 |
まとめ
一見すると数字のデータに見えてもデータがobject型になっているとすべての統計情報を表示できません。
慌てずにobject型からint型に変換して適切な情報を抽出しましょう。