

横浜国立大学理工学部建築都市環境系学科卒
一級鉄筋技能士
唎酒師
狂人のごとく特定の分野、中小企業を理解し、国の補助金を獲得します。最近は中小企業のM&Aにも挑戦中
AIはすでに多くのものが開発され、無料で公開されています。
中には人間の顔を検知するものもあり、代表的なものがYOLOという学習モデルです。
この学習モデルを使用すれば、人間が危険な場所に立ち入った際にアラームが鳴って警告してくれる等の簡単なAIは実装できるかもしれません。
カメラとパソコンをネットワーク接続すればこのようなAIを実装できるのですから、非常に便利な世の中ですね。
中小企業にとっては人間等の検知よりももっと具体的な商品(例えば鉄筋)の検知が必要ですから、学習済みのモデルを使えば何でも検知できるわけではありませんが、一般的な開発手順は同じです。
この記事では、YOLOの学習済みモデルを使って画像に何が映っているのか推論してもらう動作手順をご紹介します。

目次
YOLO V5について

「YOLO V5」は物体の位置と種類を検出する機械学習アルゴリズムです。
このAIを使えば写真に写っている要素は何なのか?その要素の位置はどこか?を教えてくれます。
YOLO V5のインストール
YOLO V5をインストールするには以下のコードを実行します。
|
1 2 3 4 |
import torch # Torch HubからYOLO V5をダウンロード model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True) |
検出してくれる要素を確認する
このモデルで検出してくれる要素の種類を確認します
|
1 2 |
for key in model.names: print(model.names[key]) |
画像の準備
AIに検出してもらう画像を準備します。

画像のコード
|
1 |
image_url = 'https://github.com/ultralytics/yolov5/raw/master/data/images/bus.jpg' |
推論を実行する
|
1 2 |
# 推論の実行 results = model(image_url) |
推論結果を確認する
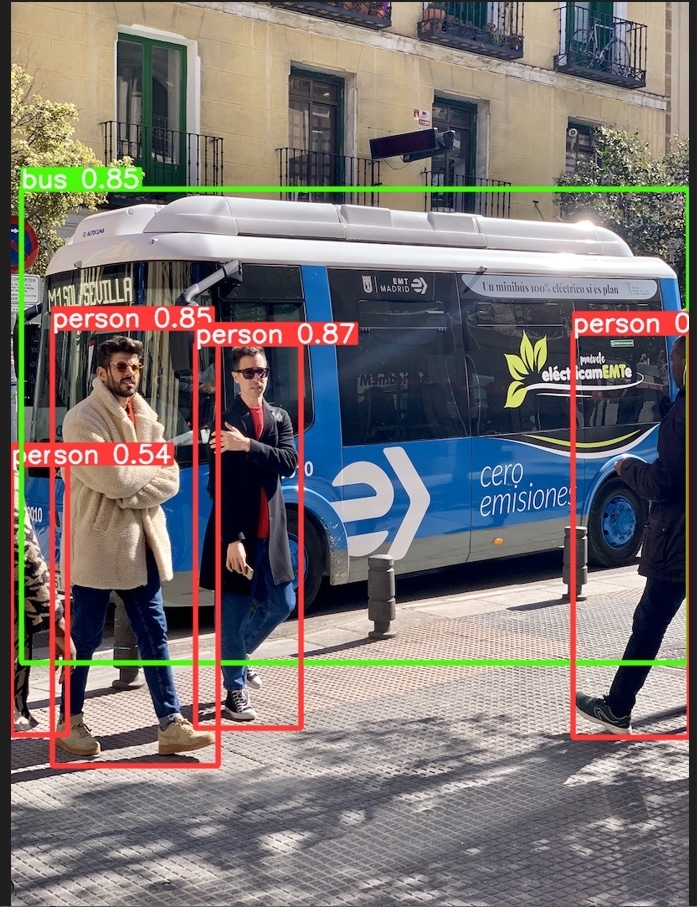
画像の用意、推論の実行が終わったら、結果を確認しましょう。
推論結果を保存する
|
1 2 3 4 5 6 7 |
import shutil import os os.chdir("./content") if os.path.exists('runs'): shutil.rmtree('runs') # 結果保存 results.save() |
plt.show()で結果を表示
|
1 2 3 4 5 |
import matplotlib.pyplot as plt import cv2 img = cv2.cvtColor(cv2.imread("runs/detect/exp/bus.jpg"), cv2.COLOR_BGR2RGB) plt.imshow(img) plt.show() |
UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.plt.show()
上記のコードを叩くと、以下のエラーが発生します。
|
1 2 3 |
<ipython-input-10-1043322c5aa7>:5: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.plt.show() </ipython-input-10-1043322c5aa7> |
このエラーの解決法として、「tkinterをインストールする」というのが一般的のようですが、plt.show()の代わりにresults.show()を使用するだけで解決できます。
|
1 2 3 4 5 |
import matplotlib.pyplot as plt import cv2 img = cv2.cvtColor(cv2.imread("runs/detect/exp/bus.jpg"), cv2.COLOR_BGR2RGB) plt.imshow(img) results.show() |
結果を表形式で出力する
|
1 |
results.pandas().xyxy[0] |
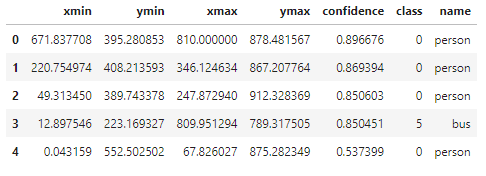
confidenceは検出の確信度であり、0~1の間で1に近いほど機械が自信を持って判定します。

まとめ
学習済みのモデルを使用すれば、上記の簡単なコードを実行するだけでAIを使用できます。
建設業では安全対策にカメラを用いた画像認識AIが使用されることが多々あります。
人間を検知するだけなら、学習済みのモデルを使用するだけで安全対策のコストを削減できるかもしれません。