

横浜国立大学理工学部建築都市環境系学科卒
一級鉄筋技能士
唎酒師
すでに学習済みのAI(Deep Learning)を使えば、すぐAIを体験できます。
ただ、たいていはこの方法で画像分類をすることはほとんどないと思います。
学習済みの分類項目が固定されてて、自分の分類したいものが含まれていないからです。
例外として、体の顔や姿勢を検知するAIは検知したいものが同じなので、学習済みのAIを使います。
今回は、自分でデータを用意して、そのデータで学習する方法を習得していきます。
難しい数学の知識はできるだけ省いてできるだけ簡単に説明します。

目次
画像分類の学習ステップ
まずは、学習のステップについて説明していきます。
- データを集める
- アノテーション(ラベル付)をする
- AIのモデルを読み込む
- 画像を読み込む
- ハイパーパラメータを決めて学習
- 精度確認
最初に画像データを集める
最初にすることはデータを集めることです。
スマフォやネットを使ってひたすらデータを集めましょう。
今回は、犬と猫の画像をpixabayから60(学習用 50 バリデーション用 10)ずつ集めました。


アノテーション(ラベル付け)をする
データを集めたら、次はアノテーション(ラベル付)です。
この作業が一番手間がかかるところです。
今回は、二種類を60つずつなので、全然大変ではありませんが、数百種類を数千枚アノテーションするとなると大変です。
アノテーションは次のようにフォルダごとに分けるだけです。

trainは学習用で、valはバリデーション用です。
フォルダには分類したい英名(cat, dog等)を入れておくと良いでしょう。
AIモデルを読み込む
画像を分類することができるAIモデルで代表的なものはいくつかあります。
pytorchではいくつかのモデルは1行で読み出すことができます。
modelの種類はpytorchドキュメントのここを参照ください。

まず一番最初に覚えると良いモデルはVGGという種類ですが、まずは、色々な種類があるのだということを覚えておきましょう。
これらのモデルは、他の位置検出やセマンティックセグメンテーションでも、部分的に使われています。
画像データを読み込む
pytorchでの画像の読み込みはtransforms, datasets, dataloadersを使います。
| 機能 | |
|---|---|
| transforms | データをリサイズなど加工する |
| datasets | データを読み込んで全データを管理 |
| dataloaders | datasetsのデータをバッチサイズに応じて、取り出す |
下記のようなイメージです。

先程のアノテーションの時のフォルダ体系にしておけば、決まったコーディングでデータの読み込みができます。
ハイパーパラメータを決めて学習
画像分類ではAIのモデルをどれにするか?など、人が精度を上げるためにいくつか調整する項目があります。
AIモデル以外は、最適化関数をどれを使うか?その学習率をどうするか?が一番重要な項目です。
| 項目 | 備考 |
|---|---|
| バッチ数 | 全体のデータからどれだけ小出ししにして学習するかの数 GPUのメモリによっては少なくする必要がある |
| 最適化関数 | どの最適化関数を使うか。adam、SGD、Adadelta等。 |
| 最適化関数のパラメータ | 学習率などの最適化関数のパラメータ |
| エポック数 | 学習データ全部を何回繰り返して学習するか 1エポック=全学習データ |
他にも精度Upのために色々な方法がありますが、最初はこの4つを調整するところから始めると良いです。
これだけでも十分な精度を出すことができます。
精度を確認
学習が完了したら、学習データとバリデーションデータの精度を確認しましょう。
オーバー、アンダーフィッティングを確認しつつ求めている精度になっているか確認します。
精度結果からモデルを変えたり、データを増やしたり、ハイパーパラメータを調整することになります。
転移学習
転移学習はすでに大量のデータを使って学習した、学習済みのAIモデルを使って、自分のデータで学習し直すことです。
これは分類している項目、数が違っても全然OKです。
転移学習を使うメリット
転移学習を使うことで、以下のメリットがあります。
- 学習データが少なくてもある程度精度が出せる
- 最終層以外は学習しないので、高速に学習できるので学習時間が短く済む
- 分類以外にも、位置検出などでも使うことができる
もう少し詳しく説明していきます。
今回使う、VGGモデルの構成を見てみましょう。
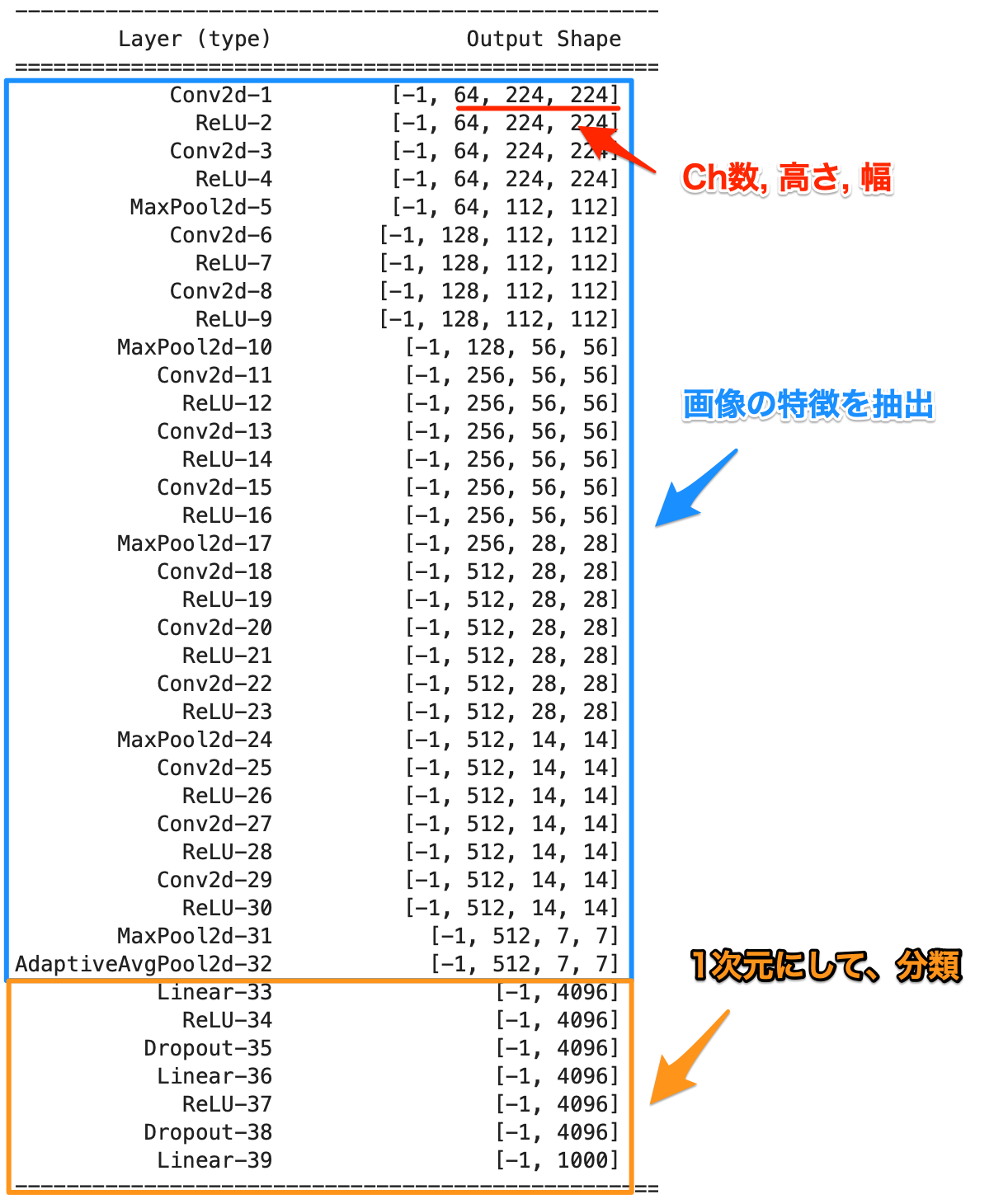
これは今は理解できなくて良いですが、AIモデルである処理の流れのサマリーです。
青いところでは、画像のエッジや質感など特徴を捉えて、オレンジ色のところで分類できるように1次元の配列の数を少なくしていきます。
わかりにくいので、図にすると以下のような感じです。
横向きに変更していますが、画像データのRGB(3ch)、高さ、幅の立方体の形を変更して行き、最終的に分類数の1次元配列にします。

すでに学習したAIでは青い箇所で画像の特徴を抽出することができているので、オレンジ色の箇所だけを自分のデータに合うように学習し直します。
これがとてもうまく機能するので、よく使われている方法になり、今回も使っていきます。
実際に学習してみる
学習までの流れが掴めたところで、実際に用意したデータを学習して、オリジナルの画像分類AIを作っていきましょう。
コード量が多くなるので、難しく感じる場合は、とりあえずは動かせるようになるところから始めてください。
動かせるようになってから、一つ一つ理解していくことがとても大事です。
データ
データを用意して、コードと同じフォルダにおいてください。
最後に確認するデータには、下記二つのデータを使います。


データとコード含むファイルを添付(ml7)しますので、ダウンロードして使用してください。
ライブラリの読み込み
まず、必要なライブラリを読み込みます。
torchとついているのがpytorch関係ですが、今回は、データ読み込みやAIモデルに関係するものも読み込みます。
|
1 2 3 4 5 6 7 8 9 |
import torch import torch.nn as nn import torch.optim as optim import torchvision from torchvision import datasets, models, transforms import numpy as np from tqdm import tqdm from PIL import Image |
データの読み込み
データ読み込みのコードは、ほぼ決まり文句です。
transformsを定義
読み込んだデータを学習済みモデルに合わせてリサイズ(224×224)、pytorchで使えるTensorに変更しています。
あとは、学習済みモデルを使うので、それに合わせた正規化をしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
size = (224, 224) data_transforms = { 'train': transforms.Compose([ transforms.Resize(size), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'val': transforms.Compose([ transforms.Resize(size), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), } |
これが一番シンプルな方法ですが、学習時に画像データを反転したり、切り取ったりすることで少ないデータでも精度が出るような工夫をすることが多いです。
データ拡張という方法になります。
datasetsを定義
データの保存先と、transformsを渡しています。
|
1 2 3 4 5 6 7 |
train_data_dir = 'dataset/train' val_data_dir = 'dataset/val' image_datasets = { 'train': torchvision.datasets.ImageFolder(train_data_dir, transform=data_transforms['train']), 'val': torchvision.datasets.ImageFolder(val_data_dir, transform=data_transforms['val']) } |
dataloaderを定義
datasetsを渡してdataloadersを作ります。
引数のbatch_sizeがデータをどれだけ細かく分けて学習するかの数字になります。
trainのbatch_size=10は、今回の100あるデータを10ずつ取り出していくということです。
batch_size(バッチサイズ)は16,32とかデータ数が多ければ、64とか適当な数字で良いです。
プラスshuffle=Trueとすることで、ランダムに取り出すようにします。
|
1 2 3 4 |
dataloaders = { 'train': torch.utils.data.DataLoader(image_datasets['train'], batch_size=10, shuffle=True), 'val': torch.utils.data.DataLoader(image_datasets['val'], batch_size=5) } |
その他
ここでは、データの数と分類項目名を取得しています。
データ数は、精度やロスの計算に使っています。
|
1 2 3 4 5 6 7 |
dataset_sizes = { 'train': len(image_datasets['train']), 'val': len(image_datasets['val']) } class_names = image_datasets['train'].classes print('分類種類:', class_names) |
|
1 |
分類種類: ['cat', 'dog'] |
モデルの調整
まず、学習済みのVGG16を読み込みます。
deviceはGPU/CPUどちらを使うかの文字列を入れています。
|
1 2 3 4 5 |
# GPU/CPUが使えるかどうか確認 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # VGG16の読み込み model = models.vgg16(pretrained=True) |
次に、VGG16の最後の層のみを学習するように変更します。
*vgg16以外のresnet18など他のモデルを使う場合はモデルに合わせて変更が必要です。
|
1 2 3 4 5 6 7 8 |
# パラメータの固定 for param in model.parameters(): param.requires_grad = False # 最後の全結合層を固定しない>ここだけ学習する last_layer = list(model.children())[-1] for param in last_layer.parameters(): param.requires_grad = True |
VGG16をそのまま使うと1000種類の分類をするようになっているので、これを2種類に変更しています。
|
1 2 3 4 |
# 分類数を1000から2つに変更 num_ftrs = model.classifier[6].in_features model.classifier[6] = torch.nn.Linear(num_ftrs, len(class_names)) model = model.to(device) |
loss関数、最適化関数の設定
まず、予測値とラベルの差であるロスを定義しますが、今回の分類はCrossEntropyLossを使えばOKです。
最適化関数は色々ありますが、今回はAdamという最適化関数で学習率は0.0001とします。
|
1 2 3 4 5 6 |
# lossを定義 criterion = nn.CrossEntropyLoss() # 色々な最適化関数 lrが学習率 0.001 0.0001などで調整 optimizer = optim.Adam(model.parameters(), lr=0.0001,) # optimizer = optim.SGD(model.parameters(), lr=0.001,) |
最適化関数は「線形回帰を使って、値を予測する」の記事の勾配効果法で説明したものと思って貰えば良いです。
ロス値が少なくなる=精度が良くなるように調整するためのアルゴリズムです。
学習処理
学習するためのコードを実装していきます。学習のループは、trainとvalを交互に、次の流れになっています。
- dataloadersから画像(inputs)とラベル(labels)を取り出す
- AIモデルで予測値(output)を取得
- 予測とラベルのロスを計算
- train時は最適化関数で学習(パラメータの更新)
- ロスと精度を確認して表示
学習関数を定義
学習用の関数を定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
def train(model, dataloader, otpimizer, criterion, num_epochs, device): """ model:学習モデル dataloader:学習、評価データのdataloader optimizer:最適化関数 crierion:ロス関数 num_epochs:学習回数 device:CPUかGPUか """ best_acc = 0.0 # 学習を繰り返す for epoch in range(num_epochs): # trainとvalを繰り返す for phase in ['train', 'val']: # モデルを学習モードか評価モードに切り替える if phase == 'train': model.train() else: model.eval() # 精度計算用 loss_sum = 0.0 acc_sum = 0.0 total = 0 # 進捗の表示 with tqdm(total=len(dataloaders[phase]),unit="batch") as pbar: pbar.set_description(f"Epoch[{epoch}/{num_epochs}]({phase})") # dataloadersからバッチサイズに応じてデータを取得 for inputs, labels in dataloaders[phase]: # 画像とラベルをGPU/CPUか切り替え inputs = inputs.to(device) labels = labels.to(device) # 予測 outputs = model(inputs) _, preds = torch.max(outputs, 1) # ロス算出 loss = criterion(outputs, labels) # 予測とラベルの差を使って学習 if phase == 'train': # ここは決まり文句 optimizer.zero_grad() loss.backward() optimizer.step() # ロス、精度を算出 total += inputs.size(0) loss_sum += loss.item() * inputs.size(0) acc_sum += torch.sum(preds == labels.data).item() # 進捗の表示 pbar.set_postfix({"loss":loss_sum/float(total),"accuracy":float(acc_sum)/float(total)}) pbar.update(1) # 1エポックでのロス、精度を算出 epoch_loss = loss_sum / dataset_sizes[phase] epoch_acc = acc_sum / dataset_sizes[phase] # 一番良い制度の時にモデルデータを保存 if phase == 'val' and epoch_acc > best_acc: print(f"save model epoch:{epoch} loss:{epoch_loss} acc:{epoch_acc}") torch.save(model, 'best_model.pth') |
関数を実行
今まで宣言してきたmodelなどを引数に10回学習していきます。
|
1 2 |
num_epochs = 10 train(model, dataloaders, optimizer, criterion, num_epochs, device) |
次のような結果が出力されれば、学習しています。

予測値とラベルの差である、lossが下がっていき、精度が1=100%に近づいていることがわかります。
テストデータで確認
以下の記事のコードを参考にしてください。
|
1 2 |
# 今回学習したモデルでテスト best_model = torch.load('best_model.pth') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 対象画像 filename = 'test_dog.jpg' # 読み込み画像をリサイズやtensorなどの方に変換 input_image = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(input_image) input_batch = input_tensor.unsqueeze(0) # GPU使える場合はGPUを使う if torch.cuda.is_available(): input_batch = input_batch.to('cuda') best_model.to('cuda') # AIの判定 with torch.no_grad(): output = best_model(input_batch) output = torch.nn.functional.softmax(output[0], dim=0) print(output.shape) # 出力結果から2種類のうちどれかを数値で取得 output = output.to('cpu').detach().numpy().copy() ind = np.argmax(output) print(class_names[ind]) |
test_dog.jpgの判定がdogとなっていて、犬猫の判定ができるAIができました。
まとめ
犬猫だけでなく、試したいデータを用意して動かしてみてください。