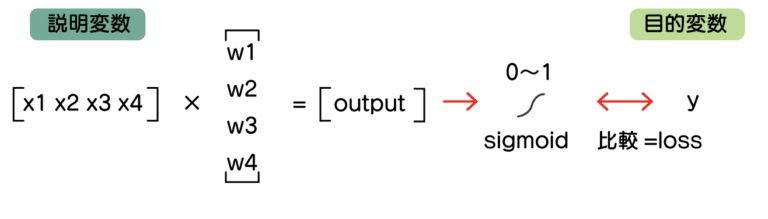

横浜国立大学理工学部建築都市環境系学科卒
一級鉄筋技能士
以前、ロジスティック回帰を紹介しました。
今回は、PyTorchで実装していきます。
この処理が大事なのは、画像の分類処理などでも、一番最後の処理は同じことをしている点です。
本記事では以下のライブラリが必要になります。
|
1 2 3 4 5 6 |
seaborn scikit-learn matplotlib pandas numpy torch |
PyTorchのインストールは公式リンクを参照ください
本記事のサンプルコード

目次
多項分類のロジスティック回帰について
前回の記事ではscikit-learnを使って、2種類の分類をしましたが、今回は分類数が3種類ある、多項分類をしていきます。
データの確認
今回はirisのデータを使います。
|
1 2 3 4 5 6 |
import seaborn as sns df = sns.load_dataset('iris') # 品種の確認 print(df['species'].unique()) # データの一部確認 df.head() |
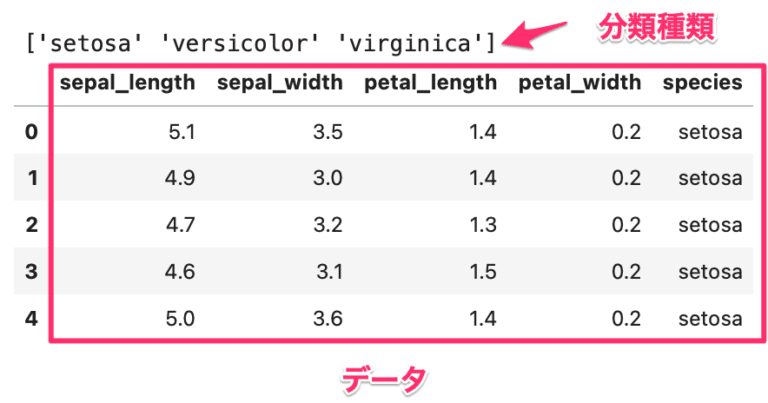
4つの特徴量(説明変数)と最後の列が分類したい種類(目的変数)が3つあります。
分類が2種類と3種類の違い
2種類と3種類で計算が変わってきます。
まず、2種類の場合は次のような計算をしていました。
わかりやすさのため、バイアス項を省略しています。
*バイアス項はy = ax + bのb(切片)のところです。
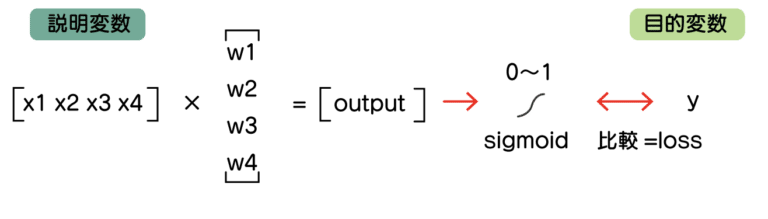
このような行列の掛け算をしていたことになります。
output = x1w1 + x2w2 + x3w3 + x4w4
の計算です。
これをsigmoid関数で0から1の数値にして、説明変数の0/1と比較していました。
これが3種類の場合は、次のようになります。
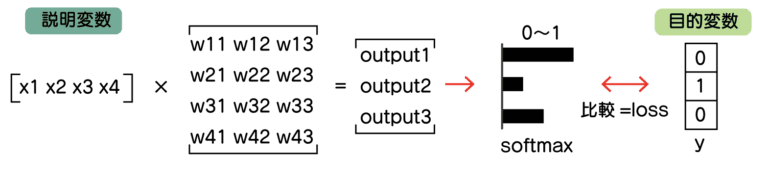
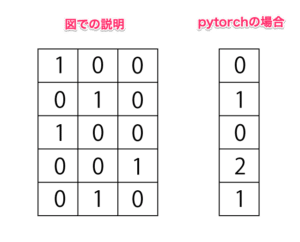
まず、目的変数を3つにして[‘setosa’ ‘versicolor’ ‘virginica’]と分けれるようにします。
例えば、setosaであれば[ 1, 0, 0]となるようにします。
これのままだと、outuputが1つだと足りませんね。
なので、計算したら、outputが3つになるように計算します。
*outputは見やすさのため縦で並べています。
outputはsoftmaxという処理をすることで、それぞれの項目がどの確率が高くなるか、0から1で表現されるようにします。
例えば、[3, 1, 0.5]という数字をsoftmaxの処理をとおすと次のようになります。
|
1 2 3 4 5 6 7 8 |
# softmaxの確認 import numpy as np def softmax(x): return np.exp(x)/np.sum(np.exp(x)) output = [3,1,0.5] print(softmax(output)) |
|
1 |
[0.82140902 0.11116562 0.06742536] |
それぞれ、0から1で表現されて、それぞれを足すと合計が1になるように計算されます。
このsoftmaxで出力された結果と目的変数の値を比較します。
計算の概要がわかったところで、これをpytorchで実装していきます。
pytorchでロジスティック回帰の実装
pytorchでロジスティック回帰を実装していきます。
どの機械学習モデルも同じですが、次のステップを踏みます。
- データの用意
- モデルを定義
- ロスを選ぶ
- 最適化関数を選ぶ
- 学習のループ
- テスト
データの用意
seabornに入っているデータのirisを使っていきます。
|
1 2 3 4 5 6 |
import seaborn as sns df = sns.load_dataset('iris') # 品種の確認 print(df['species'].unique()) # データの一部確認 df.head() |
これは、先ほど確認したものと同じです。
次は、学習用テスト用などに分けます。
- 説明変数(x)と目的変数(y)に分ける
- 目的変数のspeciesを数値の0,1,2に変換
- 学習とテストデータに分ける
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from sklearn.model_selection import train_test_split import pandas as pd # 説明変数と目的変数を分ける x = df[['sepal_width', 'sepal_length', 'petal_width', 'petal_length']].values # 目的変数は0,1,2に変更しておく df['species'] = df['species'].map({'setosa': 0, 'versicolor': 1, 'virginica': 2}) y = df['species'].values # x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.1) print(x_train.shape) print(y_train.shape) print(x_test.shape) print(y_test.shape) |
データの形も確認しています。
|
1 2 3 4 |
(135, 4) (135,) (15, 4) (15,) |
あとは、これをtorchで使えるデータにします。
まず、ライブラリを読み込見ます。
|
1 2 3 4 |
import torch from torch.utils.data import TensorDataset from torch.utils.data import DataLoader from torch.autograd import Variable |
Datasets、Datalodersを作ります。
| 機能 | |
| Datasets | データを読み込んで全データを管理 |
| Dataloaders | Datasetsのデータをバッチサイズに応じて、取り出す |
|
1 2 3 4 5 6 7 8 9 10 11 |
# データの準備 x_train = torch.from_numpy(x_train).float() x_test = torch.from_numpy(x_test).float() y_train = torch.from_numpy(y_train).float() y_test = torch.from_numpy(y_test).float() train = TensorDataset(x_train, y_train) train_loader = DataLoader(train, batch_size=10, shuffle=True) test = TensorDataset(x_test, y_test) test_loader = DataLoader(test, batch_size=5, shuffle=True) |
batch_sizeはデータを取り出すときの数ですが、これは適当な値を選定してください。
「今回は135のデータだし、10個ずつ取り出すかぁ」とかです。
説明変数のデータの形がおかしいって思った方はいるでしょうか?
先程の説明だと、目的変数を[1, 0, 0]や[0, 1, 0]にして比較するということを説明しました。
これだと、y_trainのデータの形は(135, 3)となっていて、3列のデータになるはずです。
しかし今回は、’setosa’: 0, ‘versicolor’: 1, ‘virginica’: 2と数値に置き換えているので、(135, )と1列のデータなっていています。
これは、後で出てくるCrossEntropyLossというロスの方で、うまく計算してくれているためです。
なので、PyTorchではspeciesは0,1,2,..と数値に変更すればOKです。
モデルを定義
次は、ロジスティックモデルを定義します。
図では、ピンク枠の部分です。
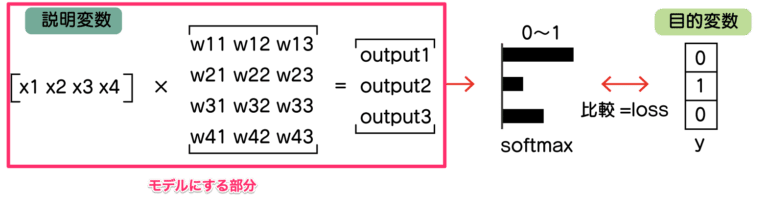
モデルには、softmaxは含めていません。
次に出てくる、CrossEntropyLossに含まれるためです。
まず、モデルを定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# ロジスティック回帰モデル class LogisticRegression(torch.nn.Module): def __init__(self, input_dim, output_dim): super(LogisticRegression, self).__init__() self.l1 = torch.nn.Linear(input_dim, output_dim) def forward(self, x): x = self.l1(x) return x |
これはモデルの設計書みたいものです。
このモデルに、入力するデータの数、出力される分類数を入力して、モデルを作ります。
今回は、 sepal_length,sepal_width,petal_length,petal_width の4つの特徴量があります。
分類数は、setosa, versicolor, virginicaの3つなので、3です。
|
1 2 3 4 5 6 |
# 特徴量の数 input_dim = 4 # 分類数 output_dim = 3 # 機械学習モデル=ロジスティック回帰 model = LogisticRegression(input_dim, output_dim) |
これで、先程の図のピンクの部分が実装できました。
もう少し、コードの補足をしておきます。
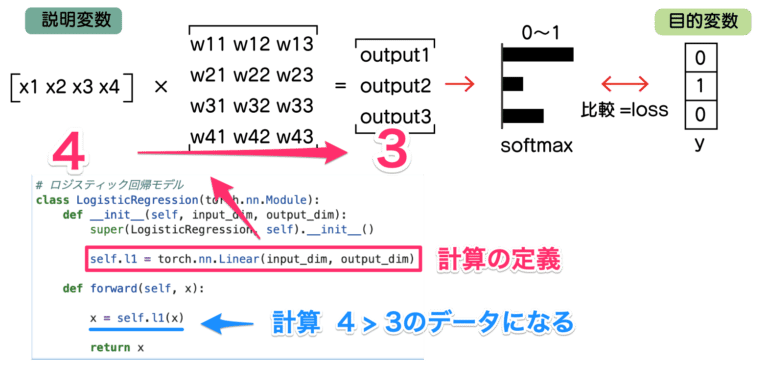
4つのデータを3つにしたいわけですが、その変換の定義はtorch.nn.Linearを使います。
これに、torch.nn.Linear(4, 3)とするだけで、計算の定義が作れます
実際の計算は、forward関数に記載する必要があります。
forwad関数の引数のxに説明変数が入ってきて、self.l1で処理することで、3つのデータが出てきます。
classという考え方を使っていますが、知らない方はこういった記述だと認識しておいてください。
ロスと最適化関数を選ぶ
モデルが決まったので、ロス、最適化関数を選んでいきます。
| メソッド | 備考 | |
| ロス | CrossEntropyLoss | 分類はこれを選んでください。 データに対してどれか1つ分類するときに使います。 例えば、1つの画像(データ)から「人」「車」など複数の検知では使えません。 |
| 最適化関数 | SGD(確率的勾配降下法) | 他にも最適化関数は色々あります。 学習率はlrで指定しますが、ここは色々調整してみてください。 |
|
1 2 3 4 5 6 |
# 学習率 lr_rate = 0.001 # lossの定義 criterion = torch.nn.CrossEntropyLoss() # 最適化関数 optimizer = torch.optim.SGD(model.parameters(), lr=lr_rate) |
図も踏まえて、どこの部分かもう少し見ていきます。
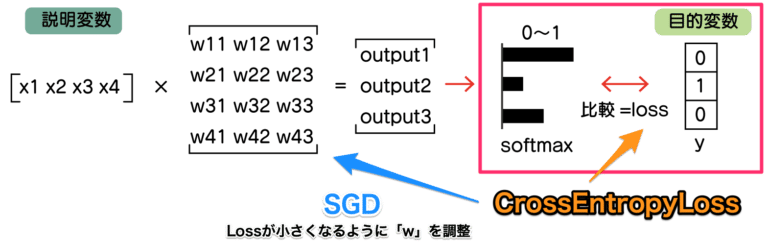
精度が出てるかどうか、CrossEntropyLossでlossを計算して、lossが小さくなるようにSGDでwを調整(最適化)します。
学習のループ
学習では、持っているデータセットを何回か繰り返して、精度をあげていきます。
loss算出 > 最適化の繰り返しですね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
loss_history = [] for epoch in range(5000): total_loss = 0 for x, y in train_loader: # 学習ステップ optimizer.zero_grad() outputs = model(x) loss = criterion(outputs, y) loss.backward() optimizer.step() total_loss += loss.item() loss_history.append(total_loss) if (epoch +1) % 100 == 0: print(epoch + 1, total_loss) |
optimizer.zero_grad()やloss.backward()、optimizer.step()は決まり文句のようなものです。

データセットを5000回繰り返して、精度をあげていっています。
学習率や、繰り返し数を変更して色々試してみてください。
lossがちゃんと下がっているか、確認してみましょう。
|
1 2 |
import matplotlib.pyplot as plt plt.plot(loss_history) |

lossがどんどん下がっています。精度が上がっている証拠です。
テスト
学習が終わったら、精度を確認します。
|
1 2 3 4 5 6 7 8 |
correct = 0 total = 0 for x, y in test_loader: outputs = model(x) _, predicted = torch.max(outputs.data, 1) total += y.size(0) correct += (predicted == y).sum().item() print('正解率', int(correct)/total*100) |
|
1 |
正解率 100.0 |
精度は100%です。
コードを捕捉します。
outputsには、(5, 3)のデータが入ります。
5はバッチサイズ=データ数で、3の方がモデルの予測結果です。
次のようになります。

各データの数値が一番大きいところが、モデルが予測した分類結果としての確率が高いものです。
torch.maxで最大値を求めると、次のようになります。
![]()
これが、予測された分類結果となります。
これを、predected=y(答え)と照合して、正解率を算出します。