

横浜国立大学理工学部建築都市環境系学科卒
一級鉄筋技能士
いろいろなところでAIが活用されており、建設業でも活用が模索され実際に使われてきています。
これからAIについて勉強したい方は、AIで使われているプログラム言語を先に学び始めることでしょう。
そんな中、どうやって学んでよいかわからない方は是非この記事を参考にしていってください。
今回は、AI開発に使われているpythonについて説明します。
これから勉強しようと思っている方が、pythonがどういったもので、どういうことができるかが理解できるように説明していきます。

目次
pythonとは
pythonの記述はwikiとか色々ありますが、以下の特徴があります。
- 人気ランキング上位
- AI開発での必須言語
- ライブラリが多い
- Windows、LinuxなどOSの違いがあっても動作する
他にもいっぱいありますが、この記事を読まれる方も、これらが勉強始めようと動機付けになったのではないでしょうか?
プログラムの集合体
自分でコードを書かなくても、誰かが書いてくれたコードを使うことができる
そのため、難しい数式を使った処理も数行で書くことができる
現状はPython3を使おう
pythonにはバージョンを大きく分けて、2と3があります。
2014年頃は対応したライブラリが少ないことから、2を使う傾向にありましたが、現状は3を選択して使用してください。
2は使う人が少なくなってきているバージョンなのであえて使う必要はありません。
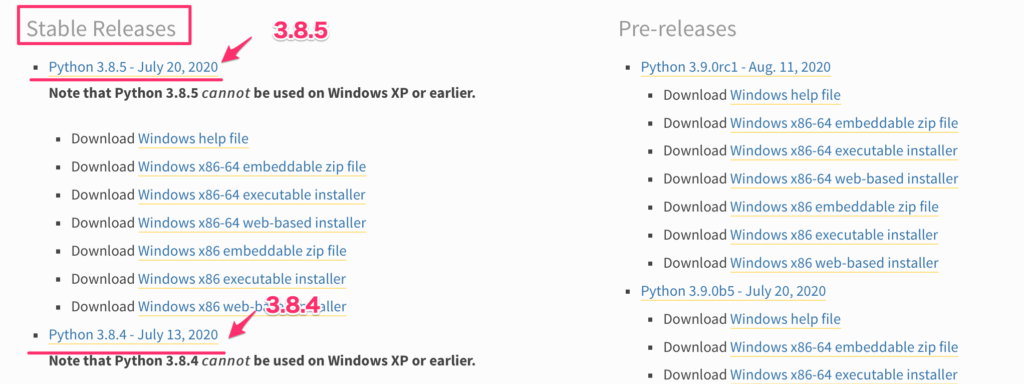
python3では、2020年時点で、3.7や3.8がありますが、その時の新しいものを使用してください。
pythonのダウンロードページのStable Releaseのバージョンを選んでおくのが良いです。
なぜpythonが選ばれるのか
なぜpythonがここまで人気になったのでしょうか?確実にAIの開発言語として使われていることがありますが、他にも多くのメリットがあります。
「見える化」「統計」「機械学習」などの処理が簡単にできる
今までデータのグラフ化や解析にはどのようなツールを使ってきたでしょうか?
Excel?JMP?MATLAB?最近では、BI(Business Intelligence)ツールなども増えてきています。
MicrosoftのPower BIなどは無料で使えるのでなかなか有用です。
最近では、pythonでデータ解析ができることも注目を集めています。
データ解析は後で詳しく説明しますが「見える化」「統計」「機械学習」などの処理が簡単にできます。
多数のライブラリがあり簡単に開発できる
pythonには色々なライブラリが用意されています。
普通に自分で最初からコードを書いていると途方もない時間がかかるものが、ライブラリをあらかじめインストールするだけで、数行でできるようになります。
下記がいくつか例になりますが、今後こんなことしたいなといった時に大抵は便利なライブラリに出会えることでしょう。
| 機能 | ライブラリ |
|---|---|
| 画像処理 | opencv、pillow |
| 機械学習 | scikit-learn |
| 表データ | pandas |
| 行列演算 | numpy |
| AI | tensorflow、keras、pytorch |
| グラフ表示 | matplotlib、seaborn |
| web操作 | selenium、 beautiful soap |
ユーザーが多いので検索で情報がすぐ手に入る
先ほどのライブラリが多いのもユーザーが多いから得られるメリットです。
さらにユーザーが多いので、困ったことがあれば本記事を見られている方のようにウェブで調べればすぐ解決しますし、本屋に行っても初学者から上級者までの本がたくさんあります。
また、最近はウェビナーと呼ばれる、ウェブ動画の講座が多くあります。
ウェビナーはYouTube、Udemy、Cousera、fastaiなど色々なところから出ています。
pythonでできること
pythonではいろいろなことができますので、いくつか紹介していきます。
データの見える化 相関を見出す
データの見える化は数字がいっぱい並んでいる状態ではなく、パッと見て何かが判断できるようにグラフ等にすることです。
pythonでは、エクセルやCSV、データベースなどのからデータを取得して、グラフにするまでは数行のコードでできます。
例えば、下記のコードでは3つのステップでグラフを描いて見える化をしています。
- ライブラリ読み込み
- CSVデータの読み込み
- グラフの表示
|
1 2 3 4 5 6 7 |
# ライブラリ読み込み import seaborn as sns import pandas as pd # CSVデータ読み込み iris = pd.read_csv('iris.csv') # グラフ表示 lmplot = sns.lmplot(x='sepal_width', y='sepal_length', hue="species", data=iris) |
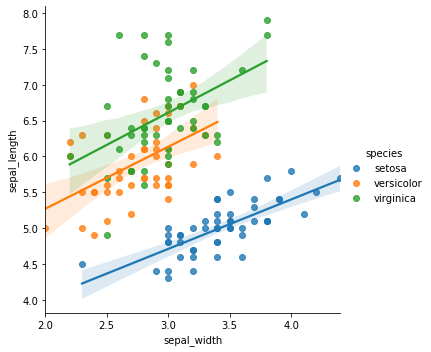
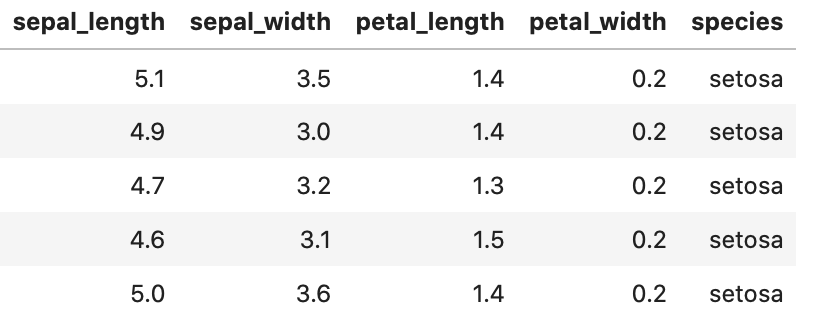
下記のようなCSVデータを読み込んで「sepal_width」「sepal_length」をグラフにしているコードだと理解しておいてください。
このグラフから「species(品種)」ごとに「sepal_width」「sepal_length」に相関の関係がありそうだということがすぐわかりますね。
このように、数字が並んでいるだけではわかりにくいデータを何かしら判断しやすい形に見える化ができます。
統計、機械学習による解析ができる
pythonでは簡単に統計、機械学習による解析ができるのも魅力の一つです。
簡単にタイタニックのデータから生存率の高いのはどういった人だったかという解析を機械学習を使ってやってみます。タイタニックのデータがどういったものか見てみましょう。
|
1 2 3 4 |
# データの読み込み import seaborn as sns titanic = sns.load_dataset("titanic") taitanic.head() |
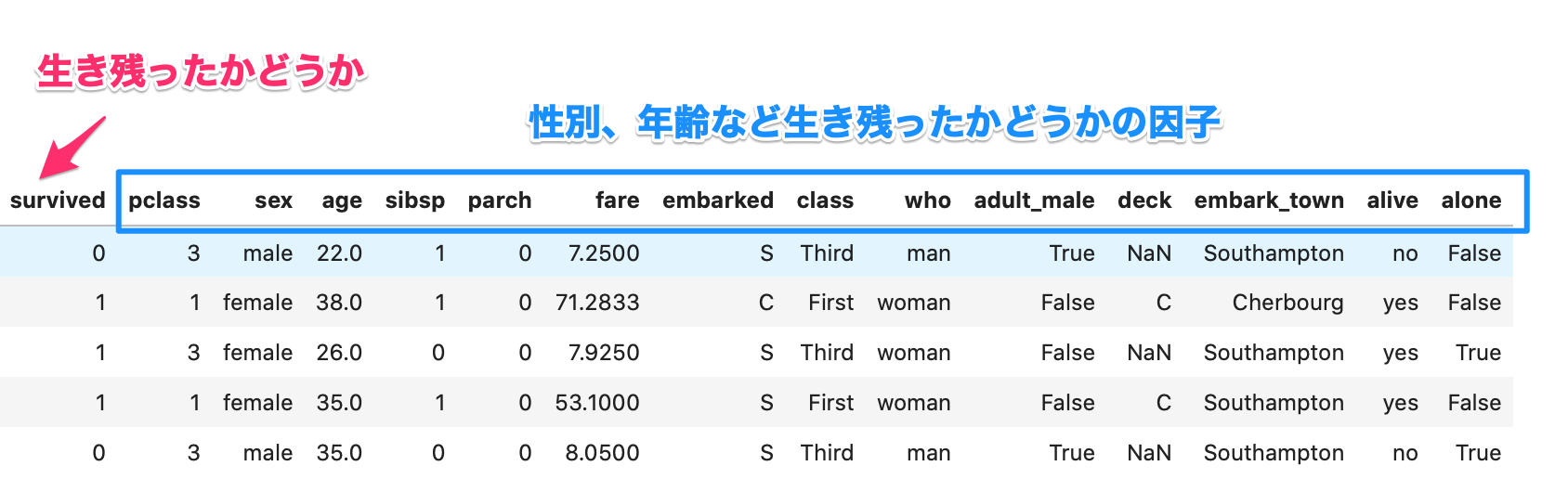
こういった表データは建設業関係なくどこ業界でも使うものだと思います。
このデータを機械学習の処理にかけて、どの因子が重要か機械に教えてもらいます。
「因子」としてますが、機械学習的には「特徴量」ですし、「要因」と置き換えても良いです。
まず、機械学習の処理ですが、使うデータの選択や、文字データを数値化する処理を入れて、機械学習の処理をしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 前処理(適当に) titanic = titanic.dropna() titanic['sex'] = titanic['sex'].map({'male': 0, 'female': 1}).astype(int) titanic['embarked'] = titanic['embarked'].map({'S': 0, 'C': 1, 'Q': 2}).astype(int) # 処理するデータを選択 train_y = titanic['survived'] train_x = titanic[['pclass', 'sex', 'age', 'sibsp', 'fare', 'embarked']] # 機械学習の学習処理 from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(random_state=0) clf = clf.fit(train_x, train_y) |
次に、機械学習の結果から、重要な因子を見える化します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# ライブラリ import matplotlib.pyplot as plt import numpy as np # 機械学習の学習結果から寄与度の高い因子を抽出 features = train_x.columns importances = clf.feature_importances_ indices = np.argsort(-importances) #降順 # グラフ化 X = range(len(indices)) Y = importances[indices] plt.bar(X,Y) plt.xticks(X, features[indices]) plt.show() |
このコードで、出来上がるグラフが下記になります。
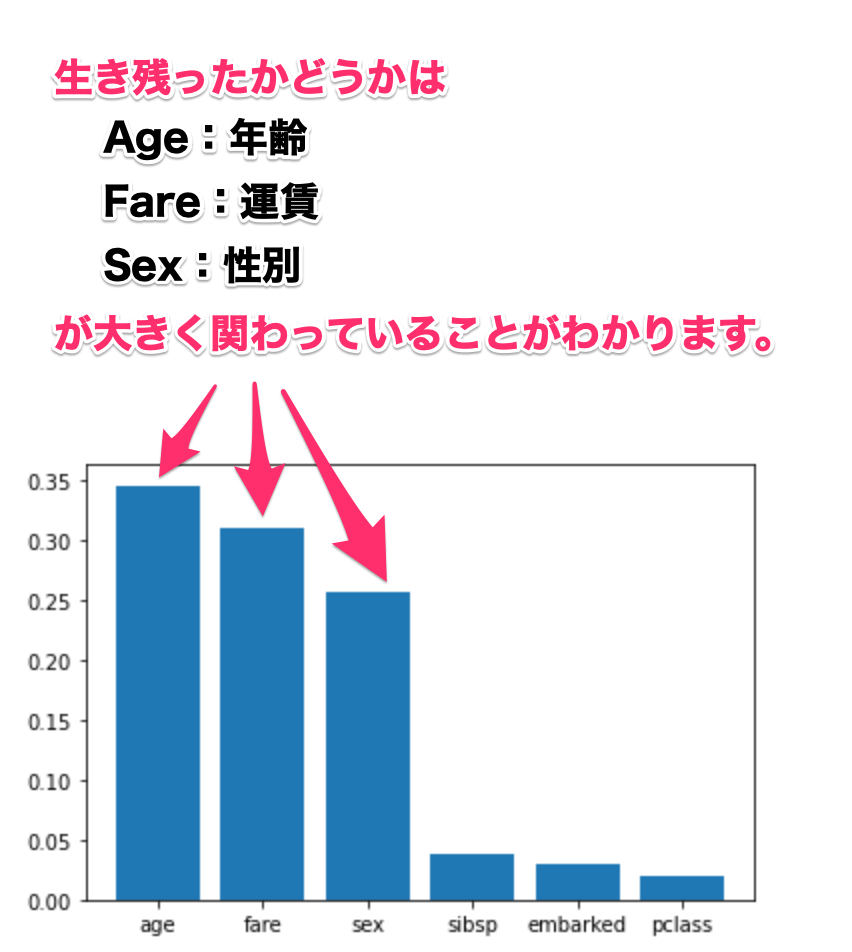
このように、そうなった原因が何であるかは機械の処理によって調べることができます。
機械学習は、分類や予測などに使いますが、こういった因子を調べることにも使えます。
ディープラーニングを使ったAI開発
ディープラーニングは機械学習の1つですが、今の翻訳、画像処理などはディープラーニングの技術によって実現されています。
難しそうなディープラーニングも画像の分類などであれば、20行程度で済みます。
試しに、次の猫の画像をAIで判定させてみます。

コードは以下のステップで処理しています。
- 画像読み込み
- AIモデルを選択
- 読み込んだ画像を前処理
- AIで分類処理
- AIの分類結果表示
コードは今は理解する必要はなく、AIの処理がこのコード量で済むということがわかればやる気も出てくるのではないでしょうか?
コードはpytorchのドキュメントを参考にしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
import torch from torchvision import models, transforms from PIL import Image # 1.画像読み込み input_image = Image.open('cat.jpg') # 2.AIモデルの定義 model = models.vgg16(pretrained=True).eval() # 3.入力画像の前処理 リサイズ、ノーマライズなど preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(input_image) input_batch = input_tensor.unsqueeze(0) # 4.画像の分類処理 if torch.cuda.is_available(): input_batch = input_batch.to('cuda') model.to('cuda') with torch.no_grad(): output = model(input_batch) output = torch.nn.functional.softmax(output[0], dim=0) output = output.to('cpu').detach().numpy().copy() ind = np.argmax(output) # 5.AIの分類結果の表示 urlからImageNetと呼ばれるデータの分類の種類のデータを取得して表示 import json import urllib url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json" res = urllib.request.urlopen(url) class_index = json.loads(res.read().decode('utf-8')) print(ind, class_index[f"{ind}"]) |
以下が処理結果です。「tabby=とら猫」であっていますね。
|
1 |
281 ['n02123045', 'tabby'] |
すでに、学習された猫とか車とかを認識するAIですが、自社製品などの判定に使うAIも学習させることができます。
無料でウェブ操作自動化ができる
数年前からRPAという単語をよく耳にします。
人が日々繰り返しているパソコン業務をロボット(プログラム)でやってもらおうというものです。
当然ですが、プログラム言語であるpythonでも人の作業を置き換えるということはよくされます。
RPAの方が簡単にできるかもしれませんが、pythonやり方を覚えると無料でできるようになります。
ここでは、そのうちのウェブ操作の自動化について簡単に紹介しますので、興味を持っていただけたらなと思います。
普段ウェブはChrome、Safariなどのブラウザを利用すると思いますが、自動化する場合もブラウザを利用します。
今回は、ChromeDriverを使い、次のことを自動化してみようと思います。
- yahooを開く
- 「python」を入力
- 検索する
これくらいの作業でも毎日の繰り返すとなると自動化するのが良いでしょう!
コードは以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from selenium import webdriver # yahooのURL url = "https://www.yahoo.co.jp/" # ブラウザでyahooを開く chromeOptions = webdriver.ChromeOptions() driver = webdriver.Chrome("resources/chromedriver_win32/chromedriver.exe", chrome_options=chromeOptions) driver.get(url) # 検索に「python」を入力 search_text = driver.find_element_by_xpath("/html/body/div/div/header/section[1]/div/form/fieldset/span/input") search_text.send_keys("python") # 検索ボタンを押す login_button = driver.find_element_by_xpath("/html/body/div/div/header/section[1]/div/form/fieldset/span/button") login_button.click() # ウェイト import time time.sleep(10) |
実行すると、Chromeが立ち上がって、「python」を検索してくれます。
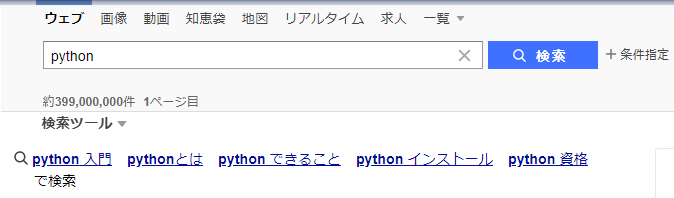
検索だけではイメージがつきにくいかもしれませんが、他にも
- 検索して決まった箇所のデータの取得
- データのダウンロード、アップロード
などのウェブ操作が自動でできるようになります。
ウェブアプリケーションのバックエンド処理
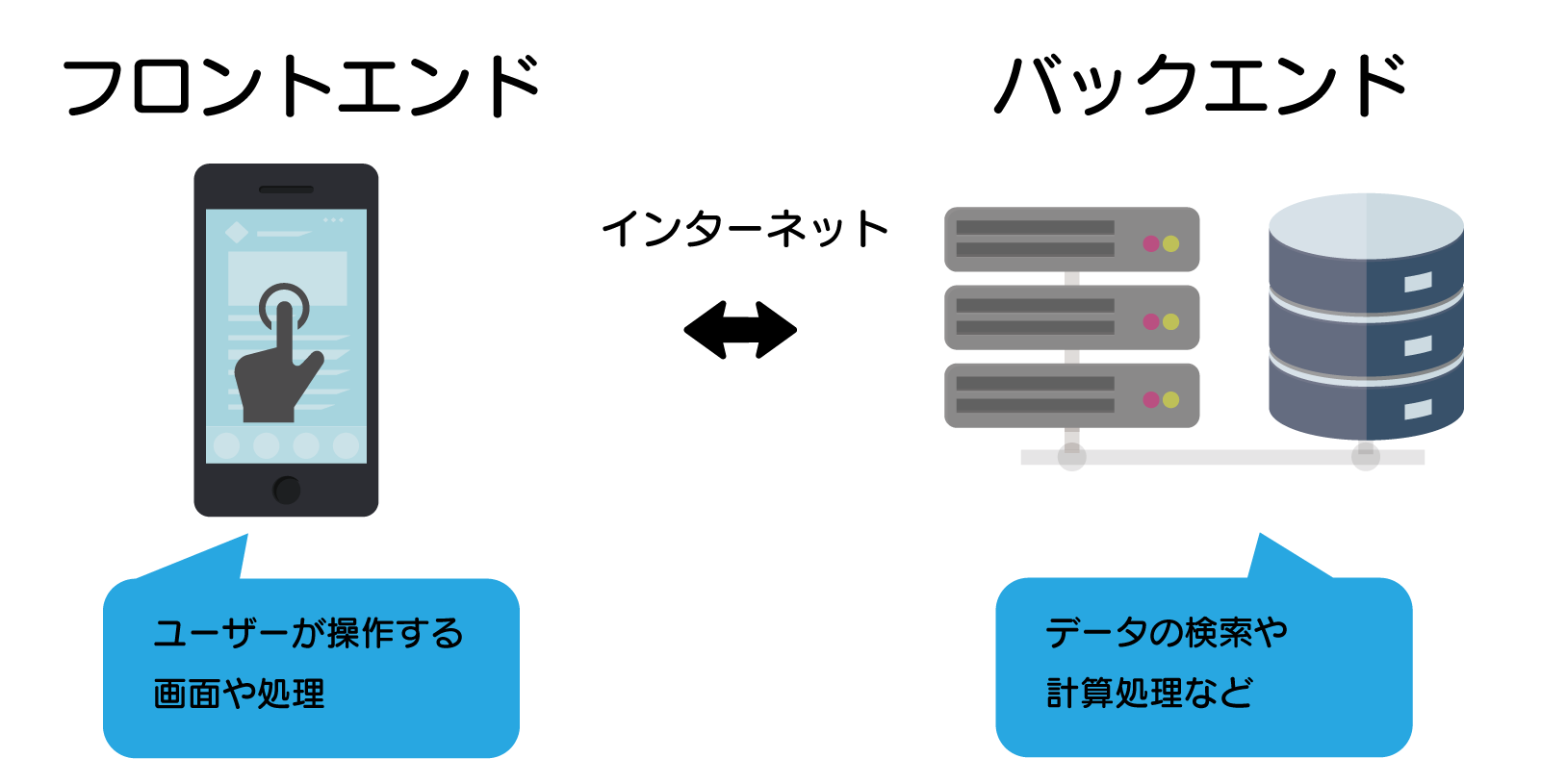
ウェブアプリケーションのバックエンド処理というのは、いわゆるサーバーサイド側の処理です。
といっても、馴染みのない方にはわかりにくいですが、ウェブアプリケーションは「ユーザー側で操作する画面や処理」と「サーバー側のデータ検索などの処理」にわかれて動いています。
バックエンド側にpythonを使うこともできるので、AIの処理などをウェブアプリケーションに使うことができます。
ウィンドウアプリケーション開発
パソコン業務では皆さんが大抵このウィンドウアプリケーションを使うので、一番馴染みがあるアプリケーションになると思います。
pythonであれば、WindwosやLinux両方で動くウィンドウアプリケーションの開発が可能です。
ユーザーに使ってもらうときにはやはり、ボタンなどの操作画面があると受け入れてもらいやすいのではないでしょうか?
まとめ
どうでしょう?これからpythonを習得しようと思っている方が、pythonがどういったもので、何ができるかがわかったでしょうか?
どういったアプリを作りたいかがpythonを習得するための大事なモチベーションになるので、是非作りたいものをイメージながら、pythonの習得をしていってください。